-
nosql数据库技术实战
-
大小:65.98M
更新时间:23-09-10
系统:Pc
版本:v
大小:65.98M
更新时间:23-09-10
系统:Pc
版本:v
nosql数据库技术实战是一本NoSQL数据库技术实战书籍手册,本书是腾讯公司前资深后台工程师皮雄军呕心沥血之作,全书介绍NoSQL从基本操作到高级技术和核心原理,再到项目开发的所有重点知识,书中详细讲解了NoSQL的兴起原因、CAP理论、副本之间数据一致性的解决方法和水平扩展方法,并介绍了NoSQL的分类、使用场景及其在实际开发中的技术选型,既对NoSQL系统的理论做了广泛而深入的分析,又重点对Hadoop/HBase、MongoDB和Redis这三种NoSQL系统给出了具体实践,非常适合所有想全面学习NoSQL的人员阅读,也适合各种使用NoSQL进行开发的工程技术人员使用。
《nosql数据库技术实战》由浅入深,全面系统地介绍了NoSQL系统。本书既对NoSQL系统的理论进行了深入浅出的分析,又介绍了每一种NoSQL数据库在业界广泛应用的一个具体系统,理论与实战并重。本书共分5篇,12章。涵盖的内容有:NoSQL与大数据简介、NoSQL的数据一致性、NoSQL的水平扩展与其他基础知识、BigTable与Google云计算原理、Google云计算的开源版本——Hadoop、Dynamo:高可用键值对存储、LevelDb——出自Google的Key-Value数据库、Redis实战、面向文档的数据库CouchDB、MongoDB实战、MySQL基础、MySQL高级特性与性能优化。
《NoSQL数据库技术实战》涉及面广,从基本操作到高级技术和核心原理,再到项目开发,几乎涉及NoSQL系统的所有重要知识。本书适合所有想全面学习NoSQL的人员阅读,也适合各种使用NoSQL进行开发的工程技术人员使用。
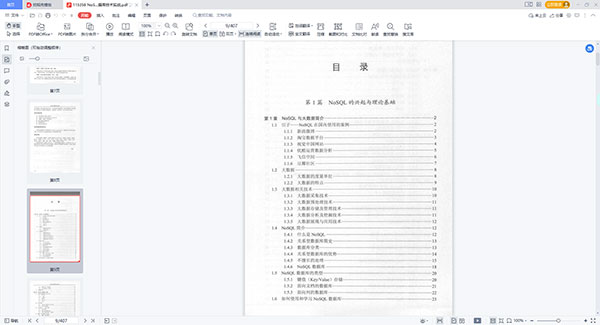
第1篇NoSQL的兴起与理论基础 第1章NoSQL与大数据简介 1.1引子--NoSQL在国内使用的案例 1.1.1新浪微博 1.1.2淘宝数据平台 1.1.3视觉中国网站 1.1.4优酷运营数据分析 1.1.5飞信空间 1.1.6豆瓣社区 1.2大数据 1.2.1大数据的度量单位 1.2.2大数据的特点 1.3大数据相关技术 1.3.1大数据采集技术 1.3.2大数据预处理技术 1.3.3大数据存储及管理技术 1.3.4大数据分析及挖掘技术 1.3.5大数据展现与应用技术 1.4NoSQL简介 1.4.1什么是NoSQL 1.4.2关系型数据库简史 1.4.3数据库分类 1.4.4关系型数据库的优势 1.4.5不擅长的处理 1.4.6NoSQL数据库 1.5NoSQL数据库的类型 1.5.1键值(Key/Value)存储 1.5.2面向文档的数据库 1.5.3面向列的数据库 1.6如何使用和学习NoSQL数据库 1.6.1始终只是一种选择 1.6.2在何种程度上信赖它 1.7云数据管理 第2章NoSQL的数据一致性 2.1传统关系数据库中的ACID 2.1.1原子性 2.1.2一致性 2.1.3隔离性 2.1.4持久性 2.1.5举例 2.2CAP理论 2.2.1NoSQL系统是分布式系统 2.2.2CAP理论阐述 2.3AP的例子--DNS系统 2.3.1DNS系统 2.3.2DNS域名解析过程 2.3.3DNS系统是最终一致性的 2.4数据一致性模型与BASE 2.4.1数据一致性模型 2.4.2BASE(BasicallyAvailable,Soft-state,Eventualconsistency) 2.5数据一致性实现方法 2.5.1Quorum系统NRW策略 2.5.2时间戳策略 2.5.3向量时钟 第3章NoSQL的水平扩展与其他基础知识 3.1所有数据存放在一个服务器上 3.2分片(Sharding) 3.3主从复制 3.4对等(PeerToPeer)复制 3.5复制和分片的同时使用 3.6数据水平扩展的方法总结 3.7分片对数据的划分方式 3.7.1Range-BasedPartitioning 3.7.2Round-Robin 3.8一致性hash算法(ConsistentHashing) 3.8.1基本场景 3.8.2hash算法和单调性 3.8.3ConsistentHashing算法的原理 3.8.4虚拟节点 3.9磁盘的读写特点及五分钟法则 3.9.1磁道、扇区、柱面和磁头数 3.9.2固态硬盘(SSD):随机读写速度快 3.9.3内存:读写速度极快 3.9.4五分钟法则 3.10不要删除数据 第2篇列式NoSQL系统 第4章BigTable与Google云计算原理 4.1云计算 4.1.1云计算的概念 4.1.2云计算发展现状 4.1.3云计算实现机制 4.1.4网格计算与云计算 4.2Google文件系统GFS 4.2.1系统架构 4.2.2容错机制 4.2.3系统管理技术 4.3并行数据处理MapReduce 4.3.1产生背景 4.3.2编程模型 4.3.3实现机制 4.4分布式锁服务Chubby 4.4.1Paxos算法 4.4.2Chubby系统设计 4.4.3Chubby文件系统 4.4.4通信协议 4.4.5正确性与性能 4.5分布式结构化数据表BigTable 4.5.1设计动机与目标 4.5.2数据模型 4.5.3系统架构 4.5.4主服务器 4.5.5子表服务器 4.5.6性能优化 第5章Google云计算的开源版本--Hadoop 5.1Hadoop简介 5.1.1Hadoop发展史 5.1.2ApacheHadoop项目及体系结构 5.2Hadoop产生的原因 5.2.1海量的数据 5.2.2数据的存储和分析 5.3Hadoop和其他系统的比较 5.3.1和关系型数据库管理系统(RDBMS)的比较 5.3.2和网格计算的比较 5.4HDFS的架构设计 5.4.1前提和设计目标 5.4.2Namenode和Datanode 5.4.3文件系统的Namespace 5.4.4数据复制 5.4.5文件系统元数据的持久化 5.4.6通讯协议 5.4.7健壮性 5.4.8数据组织 5.4.9可访问性 5.4.10空间的回收 5.5安装Hadoop 5.5.1安装JDK1. 5.5.2安装Hadoop 5.6HDFS操作 5.6.1使用FSShell命令操作HDFS 5.6.2编程读写HDFS 5.7Hadoop中的MapReduce模型 5.7.1MapReduce计算模型 5.7.2Hadoop中的HelloWorld程序 5.7.3运行MapReduce程序1 5.7.4Hadoop中的HelloWorld程序--新的API 5.7.5MapReduce的数据流和控制流 5.8Zookeeper 5.8.1Zookeeper配置安装 5.8.2Zookeeper的数据模型 5.8.3Zookeeper的基本使用 5.8.4ZooKeeper典型的应用场景 5.8.5统一命名服务(NameService) 5.8.6共享锁(Locks) 5.8.7队列管理 5.8.8Zookeeper总结 5.9HBase 5.9.1简介 5.9.2逻辑视图 5.9.3物理存储 5.9.4系统架构1 5.9.5关键算法/流程 5.10HBase的安装和配置 5.11HBase使用例子 第3篇Key/ValueNoSQL系统 第6章Dynamo:Amazon的高可用键值对存储 6.1简介 6.2背景 6.2.1系统假设和要求 6.2.2服务水平协议(SLA) 6.2.3设计考虑 6.3系统架构 6.3.1系统接口 6.3.2划分算法 6.3.3复制 6.3.4版本的数据 6.3.5执行get()和put()操作 6.3.6故障处理:暗示移交(HintedHandoff) 6.3.7处理永久性故障:副本同步 6.3.8会员和故障检测 6.3.9添加/删除存储节点 6.4实现 6.5Amazon使用的经验与教训 6.5.1平衡性能和耐久性 6.5.2确保均匀的负载分布 6.5.3不同版本:何时以及有多少 6.5.4客户端驱动或服务器驱动协调 6.5.5权衡后台和前台任务 6.5.6讨论 6.6结论 第7章LevelDb--出自Google的Key-Value数据库 7.1LevelDb简介 7.2LevelDb的静态部分 7.2.1整体架构 7.2.2log文件 7.2.3SSTable文件 7.2.4MemTable详解 7.3LevelDb的动态部分 7.3.1写入与删除记录 7.3.2读取记录 7.3.3Compaction操作 7.3.4LevelDb中的Cache 7.3.5Version、VersionEdit和VersionSet 第8章Redis实战 8.1Redis安装与准备 8.1.1下载与安装 8.1.2配置文件修改 8.1.3启动Redis 8.1.4停止Redis 8.2Redis所支持的数据结构 8.2.1String 8.2.2List 8.2.3Set 8.2.4Hash/哈希/散列 8.2.5有序集合/Zset 8.3Key操作命令 8.3.1概述 8.3.2命令示例 8.4事物 8.4.1事物概述 8.4.2相关命令 8.4.3命令示例2 8.4.4WATCH命令和基于CAS的乐观锁 8.5Redis的主从复制 8.5.1Redis的Replication 8.5.2Replication的工作原理 8.5.3如何配置Replication 8.5.4应用示例 8.6Redis的持久化 8.6.1持久化机制 8.6.2RDB机制的优势和劣势 8.6.3AOF机制的优势和劣势 8.6.4其他 8.7Redis的虚拟内存 8.7.1简介 8.7.2应用场景 8.7.3配置 8.8pipeline/管线 8.8.1请求应答协议和RTT 8.8.2管线(pipelining) 8.8.3Benchmark2 8.9实例2 第4篇文档型NoSQL系统 第9章面向文档的数据库CouchDB 9.1CouchDB介绍 9.1.1基本概念 9.1.2扩展概念 9.2CouchDB安装与配置 9.3RESTAPI 9.3.1数据库RESTAPI 9.3.2文档RESTAPI 9.3.3视图RESTAPI 9.3.4附件RESTAPI2 9.4为应用建模2 9.4.1描述实体2 9.4.2描述一对一和一对多关系 9.4.3描述多对多关系 9.5实战开发 9.5.1开发Web应用 9.5.2使用CouchDBjQuery插件 9.5.3示例应用建模 9.5.4管理文档 9.5.5视图 9.6高级话题 9.6.1权限控制与安全 9.6.2文档更新校验 9.6.3分组 9.6.4键的排序 第10章MongoDB实战 10.1为什么要使用MongoDB 10.1.1不能确定的表结构信息 10.1.2序列化可以解决一切问题吗 10.1.3无需定义表结构的数据库 10.2MongoDB的优势和不足 10.2.1无表结构 10.2.2容易扩展 10.2.3丰富的功能 10.2.4性能卓越 10.2.5简便的管理 10.2.6MongoDB的不足 10.3基本概念 10.4Linux下MongoDB的安装和配置、启动和停止 10.4.1下载 10.4.2安装 10.4.3启动数据库 10.4.4停止数据库 10.5创建、更新及删除文档 10.5.1连接数据库 10.5.2插入记录 10.5.3_idkey 10.5.4修改记录 10.5.5删除记录 10.6查询记录 10.6.1普通查询 10.6.2条件查询 10.6.3findOne()语法 10.6.4通过limit限制结果集数量 10.7高级查询 10.7.1条件操作符 10.7.2$all匹配所有 10.7.3$exists判断字段是否存在 10.7.4Null值处理 10.7.5$mod取模运算 10.7.6$ne不等于 10.7.7$in包含 10.7.8$nin不包含 10.7.9$size数组元素个数 10.7.10正则表达式匹配 10.7.11JavaScript查询和$where查询 10.7.12count查询记录条数 10.7.13skip限制返回记录的起点 10.7.14sort排序 10.7.15游标 10.8MapReduce 10.8.1Map 10.8.2Reduce 10.8.3Result 10.8.4Finalize 10.8.5Options 10.9索引 10.9.1基础索引 10.9.2文档索引 10.9.3组合索引 10.9.4唯一索引 10.9.5强制使用索引 10.9.6删除索引 10.10性能优化 10.10.1explain执行计划 10.10.2优化器Profile 10.10.3性能优化举例 10.11性能监控 10.11.1mongosniff 10.11.2Mongostat 10.11.3db.serverStatus 10.11.4db.stats 10.11.5第三方工具 10.12ReplicaSets复制集 10.12.1部署ReplicaSets 10.12.2主从操作日志oplog 10.12.3主从配置信息 10.12.4管理维护ReplicaSets 10.12.5增减节点 10.13Sharding分片 10.13.1建立ShardingCluster 10.13.2管理维护Sharding 10.14ReplicaSets和Sharding的结合 10.14.1创建数据目录 10.14.2配置ReplicaSets 10.14.3配置3台RouteProcess 10.14.4配置ShardCluster 10.14.5验证Sharding正常工作 第5篇MySQL基础与性能优化 第11章MySQL基础 11.1CentOS6.5下MySQL的安装 11.2MySQL基本命令 11.3MySQL数据类型 11.3.1整型 11.3.2浮点型 11.3.3定点数 11.3.4字符串(char,varchar,xxxtext) 11.3.5二进制数据 11.3.6日期时间类型 11.3.7数据类型的属性 11.4创建数据库和表 11.5检索表中的数据 11.6多个表的操作3 第12章MySQL高级特性与性能优化 12.1MySQLServer系统架构 12.1.1逻辑模块组成 12.1.2各模块工作配合 12.2存储引擎 12.2.1MySQL存储引擎概述 12.2.2MyISAM存储引擎简介3 12.2.3Innodb存储引擎简介 12.3MySQL中的锁定机制 12.3.1MySQL中锁定机制概述 12.3.2合理利用锁机制优化MySQL 12.4索引与优化 12.4.1选择索引的数据类型 12.4.2索引入门 12.4.3索引的类型 12.4.4高性能的索引策略 12.4.5索引与加锁 12.5MySQL的MyISAM和Innodb的Cache优化 12.5.1MyISAM存储引擎的Cache优化 12.5.2Innodb缓存相关优化 12.6MySQL的复制 12.6.1复制对于可扩展性的意义 12.6.2复制的原理 12.6.3体验MySQL复制 12.6.4复制的常用拓扑结构 12.7可扩展性设计之数据切分 12.7.1何谓数据切分 12.7.2数据的垂直切分 12.7.3数据的水平切分 12.7.4垂直与水平联合切分的使用 12.7.5数据切分及整合方案 12.7.6数据切分与整合中可能存在的问题 12.8小结
1、下载并解压,得出pdf文件
2、如果打不开本文件,请务必下载pdf阅读器
3、安装后,在打开解压得出的pdf文件
4、双击进行阅读试读
应用信息
同类热门
热门标签
网友评论0人参与,0条评论
最新排行
考无忧全国职称计算机模拟考试系统72.88Mv2016官方版 考无忧全国职称计算机模拟考试系统是目前互联网上最优秀的一款职称计算机模拟软件,该软件功能强大,聘请了职称计算机考试命题专家作为教研顾问,紧跟国家题库,分22个科目,每个考试科目收集了300-500题练习题,与5-14套模拟考题,覆盖90%以上考题,
查看像计算机科学家一样思考python 第2版48.16M艾伦·B.唐尼pdf扫描版 像计算机科学家一样思考python 第2版是一本python语言入门书籍,由艾伦·B.唐尼编著。本书从基本的编程概念开始,一步步引导读者了解Python语言,再逐渐掌握函数、递归、数据结构和面向对象设计等高阶概念。本书第2版及其辅助代码均已升级,支
查看mysql技术内幕 第5版169.74M保罗·迪布瓦 pdf扫描版 mysql技术内幕 第5版是MySQL方面名副其实的一本著作,由保罗·迪布瓦编著,张雪平,何莉莉,陶虹共同翻译。全书向读者详细的介绍了mysql的基础知识及其有别于其他数据库系统的独特功能,其中包括sql的工作原理和mysql API的相关知识等,
查看c#高级编程第10版172.94MChristian Nagel pdf扫描版 c#高级编程第10版是C#经典名著C#高级编程的第十个版本,本书由微软开发技术代言人Christian Nagel编著,李铭翻译。全书涵盖了充分利用升级功能,积极简化工作流程所需的全部信息。作者循序渐进地讲解了Visual Studio 2015、
查看ASP.NET开发实例大全(提高卷)301.3Mpdf扫描版 ASP.NET开发实例大全(提高卷)是一本Asp动态网页开发技术的指南用书,由软件技术联盟编著。全书是《asp.net开发实战1200例》之全新升级版本,详细的介绍了ASP.NET开发从基础知识到高级应用各个层面的实例及源代码,内容丰富翔实,内含1
查看ASP.NET开发实例大全(基础卷)313.29Mpdf扫描版 ASP.NET开发实例大全(基础卷)是一本ASP.NET开发指导手册,由软件开发技术联盟编著。本书筛选、汇集了ASP.NET开发从基础知识到高级应用各个层面约600个实例及源代码,每个实例都按实例说明、关键技术、设计过程、详尽注释、秘笈心法的顺序进
查看海量网络存储系统原理与设计42.83M曹强 pdf扫描版 海量网络存储系统原理与设计是一本网络存储系统原理分析设计书籍,由曹强,黄建忠,万继光和谢长生等人共同编著。本书从设计者的角度讨论高性能、高可用性和高安全性的海量网络存储系统及其部件的设计原则、评价方法、研究手段和实现方法,同时针对一些典型系统和技术
查看